 微光工作室
微光工作室
CS-HARD-01-cache
前言
所有的现代处理器都包含一个或多个高速缓存存储器,以对这样少量的存储器提供快速的访问。这一设计的根本原因在于中央处理器与主存储器之间存在的巨大性能鸿沟。随着处理器时钟频率的飞速提升,主存的访问延迟已成为制约系统整体性能的关键瓶颈,这一现象被称为“内存墙”。
为了有效弥合这一差距,计算机设计者引入了“存储层次结构”的概念。高速缓存正是这一层次结构中至关重要的一环,它作为CPU与主存之间的高速缓冲层而存在。
高速缓存之所以能以较小的容量实现显著的性能提升,其理论基石是程序的“局部性原理”。该原理指出,程序在一段时间内的内存访问行为并非随机分布,而是倾向于集中在特定的区域。它主要表现为两种形式:
- 时间局部性:被访问过的内存位置,在不久的将来很可能被再次访问。
- 空间局部性:如果一个内存位置被访问,其附近的内存位置也很可能在不久的将来被访问。
本项目的任务就是实现一个高速缓存模拟器。通过编程模拟缓存的命中、未命中以及数据替换等行为,你将对缓存的组织结构、地址映射和替换策略有深入的、实践性的理解。
Step 1 前置知识学习
任务 :
了解存储层次结构,尤其是高速缓存 (L1, L2, L3) 在其中所处的位置,简单理解寄存器、各级缓存、主存与磁盘之间的速度、容量和成本关系。
了解缓存的基本原理和缓存的地址映射
了解缓存的核心操作与算法
- 缓存未命中时使用的替换策略(LRU ,FIFO,Random等)
- 缓存写入时使用的策略
了解量缓存性能的关键指标
- 命中率与 和 未命中率
- 平均访存时间
要求
- 将任务中问题用你自己的语言描述讲解,可配图
Step 2 实现一个你的cache模拟器
实现一个高速缓存模拟器也许对你并不容易,但别担心,只需要将大问题分解成一个个小问题,相信你也能实现
高速缓存模拟器介绍
该高速缓存模拟器(以下简称模拟器)支持 4 个参数:
-s组索引的位数-E行数-b块大小B = 2^b-t输入文件trace的路径
其中前三个参数描述了一个高速缓存存储器,可以参考下图
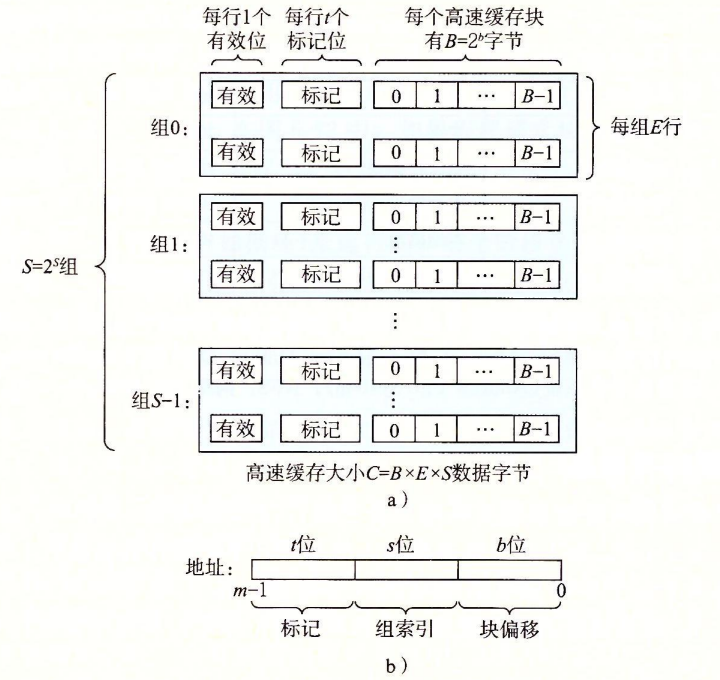
第四个参数给出了输入文件的路径
模拟器输入与输出
在输入文件中我们将给出模拟器的指令,其中每一行都是一次独立操作
输入文件格式遵循 [space]operation address, size ,其中操作有三种
L加载数据S存储数据M修改数据
而 address 为 64 位,以 16 进制给出,size 以字节为单位
你的程序面对每个操作需要给出模拟的结果,分为三种
hit命中miss不命中eviction驱赶,进行了替换操作
代码编写
缓存组结构
本题缓存组和缓存行使用双向链表进行实现,本题需要你 模拟和分析缓存的性能,可以不真正存储数据
typedef struct cache_line { int tag; // 存储地址的标签(tag)部分 // int data struct cache_line* prev; // 指向前一个节点的指针 struct cache_line* next; // 指向后一个节点的指针 } cache_line; // 定义缓存组结构体 // 每个组本质上是一个缓存行的集合。 typedef struct cache_set { int len; // 当前组中已存储的缓存行数量 cache_line* head; // 指向链表头部的指针(LRU端) cache_line* tail; // 指向链表尾部的指针(MRU端) } cache_set;typedef struct cache_line { int tag; // 存储地址的标签(tag)部分 // int data struct cache_line* prev; // 指向前一个节点的指针 struct cache_line* next; // 指向后一个节点的指针 } cache_line; // 定义缓存组结构体 // 每个组本质上是一个缓存行的集合。 typedef struct cache_set { int len; // 当前组中已存储的缓存行数量 cache_line* head; // 指向链表头部的指针(LRU端) cache_line* tail; // 指向链表尾部的指针(MRU端) } cache_set;Cache 替换算法
本题使用
LRU算法,即将最近最少使用的内容替换掉- 请你思考再本题的缓存组结构下如何使用
LRU算法
- 请你思考再本题的缓存组结构下如何使用
请你仔细阅读代码后,根据代码注释给出的要求完成你的模拟器
#include <getopt.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <stdarg.h>
#include <unistd.h>
#include <stdbool.h>
#include <math.h>
#include <assert.h>
#include <time.h>
// 读取文件时每行的最大长度
#define MAXLINE 100
// 全局变量,用于存储缓存的参数
// s: 组索引的位数 (number of set index bits)
// S: 缓存组的数量 (number of sets), S = 2^s
// E: 每个组的行数 (associativity, number of lines per set)
// b: 块内偏移的位数 (number of block bits)
int s, S, E, b;
// 定义缓存行结构体
typedef struct cache_line {
int tag; // 存储地址的标签(tag)部分
int data
struct cache_line* prev; // 指向前一个节点的指针
struct cache_line* next; // 指向后一个节点的指针
} cache_line;
// 定义缓存组结构体
// 每个组本质上是一个缓存行的集合。
// 使用双向链表来管理这些行,以便高效实现LRU策略。
typedef struct cache_set {
int len; // 当前组中已存储的缓存行数量
cache_line* head; // 指向链表头部的指针
cache_line* tail; // 指向链表尾部的指针
} cache_set;
/**
* @brief 总结并打印缓存模拟的统计数据。
*
* @param hits 命中总次数。
* @param misses 未命中总次数。
* @param evictions 驱逐总次数。
*/
void printSummary(int hits, int misses, int evictions)
{
printf("hits:%d misses:%d evictions:%d\n", hits, misses, evictions);
FILE* output_fp = fopen(".csim_results", "w");
assert(output_fp);
fprintf(output_fp, "%d %d %d\n", hits, misses, evictions);
fclose(output_fp);
}
/**
* @brief 打印错误信息到标准错误流并退出程序。
*
* @param msg 格式化的错误信息字符串。
* @param ... 可变参数,用于格式化字符串。
*/
void err_sys(const char *msg, ...) {
char buf[MAXLINE];
va_list ap;
va_start(ap, msg);
vsnprintf(buf, MAXLINE - 1, msg, ap);
va_end(ap);
strcat(buf, "\n");
fputs(buf, stderr);
fflush(NULL);
exit(0);
}
/**
* @brief 将一个缓存行节点插入到缓存组队列的尾部。
* @brief 这是LRU策略的一部分,最近使用的项放在队尾(MRU端)。
* 此函数需要处理链表为空和不为空两种情况。
*
* @param set 指向目标缓存组的指针。
* @param ptr 指向要插入的缓存行节点的指针。
*/
void cache_insert(cache_set* set, cache_line* ptr) {
}
/**
* @brief 模拟一次缓存操作(命中、未命中、驱逐)。
* @brief 采用LRU(最近最少使用)替换策略。
*
* @param set 指向要操作的缓存组的指针。
* @param address_tag 访问地址的标签(tag)部分。
* @return 0 表示命中(hit),1 表示未命中(miss),2 表示未命中且有驱逐(miss eviction)。
*/
int cache_operate(cache_set* set, int address_tag) {
}
/**
* @brief 初始化一个缓存组
*
* @param set 指向要初始化的缓存组的指针。
*/
void cache_init(cache_set* set) {
}
/**
* @brief 运行缓存模拟。
* @brief 此函数负责初始化缓存、读取trace文件并逐行模拟。
*
* @param filename 要读取的trace文件名。
* @param flagV 是否启用详细输出模式的标志。
*/
void run_simulation(const char* filename, bool flagV) {
// 提示:你可按照以下步骤完成该函数
// 1. [初始化统计变量] 定义并初始化 hits, misses, evictions 计数器为 0。
// 2. [打开文件] 记得处理失败情况
// 3. [初始化缓存]
// 4. [读取和处理Trace文件]
// 5. [计算地址部分]
// 6. [执行模拟]
// 7. [释放内存]
// 8. [调用 printSummary]
}
/**
* @brief 程序主入口。
* @brief 负责解析命令行参数,保存到全局变量并调用模拟器核心函数。
*
* @param argc 命令行参数数量。
* @param argv 命令行参数数组。
* @return 成功时返回 0。
*/
int main(int argc, char *argv[]) {
// 提示:
// 需要检查用户输出了不合法参数
return 0;
}#include <getopt.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <stdarg.h>
#include <unistd.h>
#include <stdbool.h>
#include <math.h>
#include <assert.h>
#include <time.h>
// 读取文件时每行的最大长度
#define MAXLINE 100
// 全局变量,用于存储缓存的参数
// s: 组索引的位数 (number of set index bits)
// S: 缓存组的数量 (number of sets), S = 2^s
// E: 每个组的行数 (associativity, number of lines per set)
// b: 块内偏移的位数 (number of block bits)
int s, S, E, b;
// 定义缓存行结构体
typedef struct cache_line {
int tag; // 存储地址的标签(tag)部分
int data
struct cache_line* prev; // 指向前一个节点的指针
struct cache_line* next; // 指向后一个节点的指针
} cache_line;
// 定义缓存组结构体
// 每个组本质上是一个缓存行的集合。
// 使用双向链表来管理这些行,以便高效实现LRU策略。
typedef struct cache_set {
int len; // 当前组中已存储的缓存行数量
cache_line* head; // 指向链表头部的指针
cache_line* tail; // 指向链表尾部的指针
} cache_set;
/**
* @brief 总结并打印缓存模拟的统计数据。
*
* @param hits 命中总次数。
* @param misses 未命中总次数。
* @param evictions 驱逐总次数。
*/
void printSummary(int hits, int misses, int evictions)
{
printf("hits:%d misses:%d evictions:%d\n", hits, misses, evictions);
FILE* output_fp = fopen(".csim_results", "w");
assert(output_fp);
fprintf(output_fp, "%d %d %d\n", hits, misses, evictions);
fclose(output_fp);
}
/**
* @brief 打印错误信息到标准错误流并退出程序。
*
* @param msg 格式化的错误信息字符串。
* @param ... 可变参数,用于格式化字符串。
*/
void err_sys(const char *msg, ...) {
char buf[MAXLINE];
va_list ap;
va_start(ap, msg);
vsnprintf(buf, MAXLINE - 1, msg, ap);
va_end(ap);
strcat(buf, "\n");
fputs(buf, stderr);
fflush(NULL);
exit(0);
}
/**
* @brief 将一个缓存行节点插入到缓存组队列的尾部。
* @brief 这是LRU策略的一部分,最近使用的项放在队尾(MRU端)。
* 此函数需要处理链表为空和不为空两种情况。
*
* @param set 指向目标缓存组的指针。
* @param ptr 指向要插入的缓存行节点的指针。
*/
void cache_insert(cache_set* set, cache_line* ptr) {
}
/**
* @brief 模拟一次缓存操作(命中、未命中、驱逐)。
* @brief 采用LRU(最近最少使用)替换策略。
*
* @param set 指向要操作的缓存组的指针。
* @param address_tag 访问地址的标签(tag)部分。
* @return 0 表示命中(hit),1 表示未命中(miss),2 表示未命中且有驱逐(miss eviction)。
*/
int cache_operate(cache_set* set, int address_tag) {
}
/**
* @brief 初始化一个缓存组
*
* @param set 指向要初始化的缓存组的指针。
*/
void cache_init(cache_set* set) {
}
/**
* @brief 运行缓存模拟。
* @brief 此函数负责初始化缓存、读取trace文件并逐行模拟。
*
* @param filename 要读取的trace文件名。
* @param flagV 是否启用详细输出模式的标志。
*/
void run_simulation(const char* filename, bool flagV) {
// 提示:你可按照以下步骤完成该函数
// 1. [初始化统计变量] 定义并初始化 hits, misses, evictions 计数器为 0。
// 2. [打开文件] 记得处理失败情况
// 3. [初始化缓存]
// 4. [读取和处理Trace文件]
// 5. [计算地址部分]
// 6. [执行模拟]
// 7. [释放内存]
// 8. [调用 printSummary]
}
/**
* @brief 程序主入口。
* @brief 负责解析命令行参数,保存到全局变量并调用模拟器核心函数。
*
* @param argc 命令行参数数量。
* @param argv 命令行参数数组。
* @return 成功时返回 0。
*/
int main(int argc, char *argv[]) {
// 提示:
// 需要检查用户输出了不合法参数
return 0;
}要求
完成你的模拟器编写,并运行测试用例
-s 1 -E 1 -b 2 L 0,1 L 1,1 L 2,1 L 3,1 S 4,1 L 5,1 S 6,1 L 7,1 S 8,1 L 9,1 S a,1 L b,1 S c,1 L d,1 S e,1 M f,1-s 1 -E 1 -b 2 L 0,1 L 1,1 L 2,1 L 3,1 S 4,1 L 5,1 S 6,1 L 7,1 S 8,1 L 9,1 S a,1 L b,1 S c,1 L d,1 S e,1 M f,1提交你的.c文件以及运行结果图
测试更多样例
扩展
任务
- 尝试实现更多淘汰策略
- 对你的模拟器进行大规模测试
提示
- 了解
srand和rand等函数,随机化测试 - 了解如何编写
bash脚本文件,高效运行测试文件
要求
- 描述测试思路,用图片提交测试结果
需要提交的内容及要求
README文件,包含做题过程与个人思路
做题中的C语言文件与运行截图
其他相关佐证个人学习能力与求解过程的证明材料
本题提交方式
出题人联系方式
dwdyy QQ:3403504034