 微光工作室
微光工作室
CS-EASY-03 编译原理引入
Part 1. 基本概念
什么是编译
计算机语言
计算机语言(Computer Language)指用于人与计算机之间通讯的语言。计算机语言是人与计算机之间传递信息的媒介。计算机系统最大特征是指令通过一种语言传达给机器。为了使电子计算机进行各种工作,就需要有一套用以编写计算机程序的数字、字符和语法规划,由这些字符和语法规则组成计算机各种指令(或各种语句)。这些就是计算机能接受的语言。具体而言,计算机语言可以大致分为“机器语言”、“汇编语言”、“高级语言”。而通过编译技术,就可以让容易编写的高级语言变成容易让机器理解的二进制程序。你可以通过自学了解计算机和计算机语言的发展史,对先人的理解可以帮助你树立一个更好的计算机视角。
通过上述内容,你对于编译应该有了一个初步的感觉,准确来说,编译(Compile)就是指:由一个程序(称为 “编译器”)将 “高级编程语言代码”(人写的)翻译成 “机器语言代码”(计算机能直接执行的)的过程。
举个例子:
如果我让你直接回答这个问题:ᠢ ᠬᠦᠭᠦᠭ ᠢ ᠭᠡᠳᠦᠷ ᠮᠡᠨ。你肯定会束手无策,这很正常,因为我们中的绝大多数人应该都看不懂蒙古语😇;但是如果我先给你翻译成中文:“一加一等于几”。是不是一下子清晰起来了。当我们用高级语言编写程序时也是一个道理,计算机是无法直接理解我们用高级语言编写的程序的,这个时候就需要有一个“翻译”,将我们的高级语言翻译成汇编语言(后续还要继续转化为机器语言)或者机器语言,最终得到计算机可以直接理解的内容,从而准确地执行相关操作。其中,这个“翻译”的过程就叫做编译。而承担这个“翻译”任务的软件系统,我们就称之为编译器。
接下来,请你尝试构建源程序、编译器和目标程序之间的关系图。另外请自行了解解释器,简述编译器和解释器的主要区别,并分别列举一个实际应用场景。
一个编译器的结构
编译器通常分为前端和后端两部分。前端负责分析源程序并生成中间代码,后端则将中间代码转换为目标机器代码。
具体来说:
前端包括以下几个步骤:
词法分析: 将源程序的字符流分解为记号流(Tokens)。例如,
while(value!=100){ num++; }中的while、(、value等都是记号。请你自行了解编译过程中的Token具体是什么,简述为什么需要将源代码转换为Token流。一般而言,根据程序设计语言的特点,单词可以分为五类:关键字、标识符、常量、运算符、界符。请你自行了解这五种分类的具体依据,尝试将int a = 1;和while(value!=100){ num++; }分别按这五类进行词法分析语法分析: 根据编程语言的语法规则,将词法分析生成的记号流(Tokens) 组合成有意义的语法单位(如表达式、语句、函数等),最终形成语法树(一种树状结构,直观展示代码的层级关系)。核心任务是验证 Token 流是否符合程序设计语言的语法规则,并用树形结构描述代码的语法层次。
语义分析: 是编译器在语法分析之后进行的关键阶段,其核心任务是检查程序的语义合法性(即代码的 “意义” 是否合理),并为语法树添加必要的语义信息(如类型、作用域等),为后续的中间代码生成奠定基础。
针对语法分析和语义分析,两者均涉及对记号流(Token)的处理,但两者的核心逻辑不同:前者聚焦于语法结构的合法性,后者聚焦于语义逻辑的合理性。请简述它们在检查目标、依据和对象上的主要区别。
后端包括以下几个步骤:
- 中间代码生成:生成与文法和目标机器无关的中间语言。
- 代码优化:改进中间代码,以产生执行速度较快的机器代码。
- 目标代码生成:生成最终的机器语言指令。
在本题范围内,后端部分内容简单了解即可。
这里我们给出《编译原理》(龙书)中编译过程示意图,希望可以帮助你理解
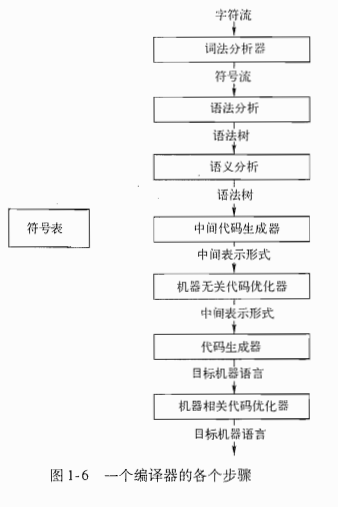
Part 2. 词法分析
接下来,我们将重点了解词法分析过程中发挥关键作用的正则表达式和有限自动机。其中正则表达式是词法规则的描述工具,其核心作用是简洁、准确地定义各类词法单元的模式;有限自动机是词法匹配的执行工具,其核心作用是高效地识别输入字符流中符合正则表达式定义的词法单元。
正则表达式
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),它是一种文本模式,同时也是计算机科学的一个概念,其中包括普通字符(例如,a 到 z 之间的字母、阿拉伯数字等)和特殊字符(称为"元字符")。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。简单来说,正则表达式就是定义了一个“规则”,我们就可以利用这个正则表达式,从文本中匹配符合这个“规则”的字符串。
下面我们举一个简单的例子,假设我们给出正则表达式abc,它就表达了一个“规则”——由字母a开始,接着是字母b,然后是c。任何包含这个连续序列的字符串,都会被该正则表达式匹配到。
上述例子中的正则表达式只有普通字符,但是在日常应用中,元字符才是正则表达式的核心组成部分。它们赋予了正则表达式 “描述模式” 的能力 —— 没有元字符,正则表达式只能进行简单的 “字面字符串匹配”;有了元字符,正则才能灵活表达复杂、多变的文本规则。下面我们给出一些基本的元字符及其含义。
| 符号 | 含义 | 示例 | 匹配结果 |
|---|---|---|---|
. | 任意字符 | a.c | "abc", "a@c" |
* | 前面的字符出现0次或多次 (尽可能多) | ab* | "a", "ab", "abb" |
+ | 前面的字符出现1次或多次 (尽可能多) | \d+ | "3", "123" |
? | 前面的元素出现0次或1次 (尽可能多) | a? | ""(空), "a" |
\d | 任意数字 | \d\d | "12", "99" |
\w | 字母/数字/下划线 | \w+ | "hello", "x1" |
[] | 字符集合 | [A-Za-z] | "a", "Z" |
^ | 字符串开头 | ^start | "start..." |
$ | 字符串结尾 | end$ | "...end" |
结合这些元字符,我们就可以进行实现正则表达式的灵活表达。例如,我们可以尝试为正整数设计正则表达式:
明确正整数的定义
- 正整数是大于0的整数。
- 所有可能中只出现数字0-9,且至少出现一个数字
- 不能以0开头(如:012,001均不合法)
由简到难地进行翻译
- 先考虑“只出现数字0-9,且至少出现一个” 针对至少出现一个数字,显然可以采用
+。所以我们可以写出初步的正则表达式[0-9]+。 - 再考虑“不能以0开头” 我们发现初步的正则表达式包含
0,012,不符合题意,所以尝试进行更改。我们发现正整数除第一位不能含0外,其余位上无限制。所以我们可以单独表示第一位为[1-9],后面的数字为0-9,出现0次或以上,可以表示为[0-9]*,综合起来,即为[1-9][0-9]*. - 考虑边界情况 需要注意的是,我们这里为正整数设计的正则表达式,其目的为匹配的整个字符串就是正整数,需要特别注意排除字符串局部满足条件。(如:
abc123edf中的123可以匹配,但这种匹配并不是我们想要的) 所以我们需要为正则表达式添加开头和结尾的边界限制,显然,我们需要使用^和$,即更改为^[1-9][0-9]*$
尝试从词法分析的角度考虑这一要求的意义是什么(不用提交回答)
- 先考虑“只出现数字0-9,且至少出现一个” 针对至少出现一个数字,显然可以采用
进行验证 尽可能广泛的设置一些测试样例。这里我们可以设置如下样例:
1,0,11.1,-1,1a.... 观察其中的错误案例具体由我们正则表达式中的哪一部分排除。如果发现问题,就再添加错误点的情况下重新设计。
最终我们就可以为正整数设计出一个最终的正则表达式:^[1-9][0-9]*$。
相信现在你对正则表达式已经有了初步的认识,请你依据上述给出的内容,并自行学习更多的具体运用,尝试为整数和C语言标识符(字母或下划线开头;后接字母、数字或下划线)设计正则表达式,提交附带思考步骤的作答。具体步骤可以参考上述过程,建议简化,体现你自己的思考即可。
针对同一目标,正则表达式并不唯一,所以本题言之有理即可。重点在于能够体现你自己的思考
- 正则表达式在线测试网站:Regex101 , https://regex101.com
有限自动机
有限自动机是词法分析的核心工具,用于识别符合特定规则的字符串,是正则表达式的底层实现原理,用于将正则规则转换为可执行的匹配逻辑(即可以直接用程序实现,让计算机执行正则表达式)。它主要由以下部分组成:
- 状态集合():系统可能处于的位置(如 开始状态、接受状态)
- 输入字母表(Σ):允许的输入符号(如字母、数字)
- 转移函数(δ):根据当前状态和输入符号决定下一状态
- 初始状态():起始位置(机器开始运行时的初始状态,q_0∈Q)
- 接受状态():成功匹配时的终止位置((F \subseteq Q),若机器读完输入后停在中的状态,则输入被 “接受”)。
我们同样举一个简单的例子来帮助你理解:
我们现在尝试给出一个偶数识别自动机(二进制表示)的有限自动机状态转移流程图,判断规则为识别以0结尾的二进制数。假设所有输入只包含0和1
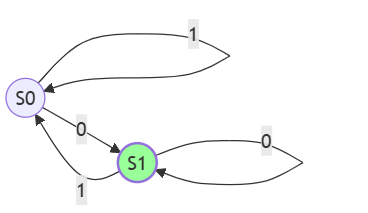
状态分析:
- S0:已读取的二进制数不是偶数(最后一位是1)
- S1:已读取的二进制数是偶数(最后一位是0)
转移规则:
- 无论当前在S0还是S1,只要读入1,则进入S0(因为最后一位是1,整个数变为奇数)
- 读入0,则进入S1(最后一位是0,整个数变为偶数)
接受条件:输入结束后停留在S1状态
初始状态:通常我们设定初始状态为S0
如果你可以理解上述的简单流程图,那么让我们来看看稍微复杂一点的:
下面我们将尝试画出针对一般输入的,正整数对应正则表达式的,有限自动机工作流程图
首先根据上述内容,我们可以知道这个正则表达式为^[1-9][0-9]*$,即我们的起始输入字符一定要是[1-9],否则就进入error,可作图如下:
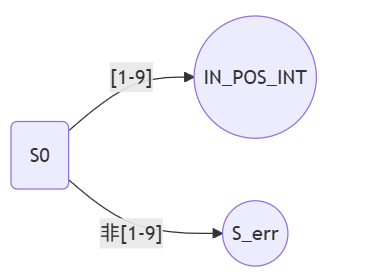
接着针对后续输入,如果是[0-9],则保持当前状态;否则就进入error,可作图如下:
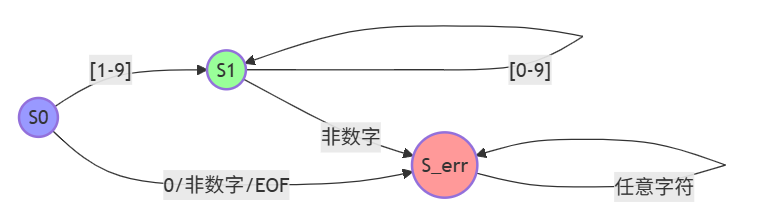
最后我们处理当整个输入字符串处理完毕(遇到EOF)时的情况,如果当前状态是接受状态(S1或S_accept),则接受该字符串(即识别为一个正整数);否则拒绝。可作图如下:
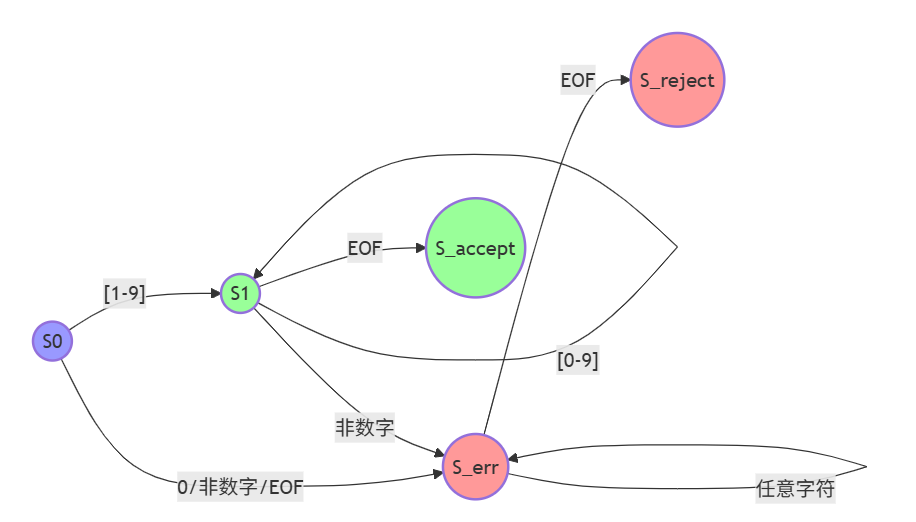
通过这两个例子,相信你对有限自动机也有了一定的了解,下面请你回答下列问题:
- 请尝试画出识别以下正则表达式的有限自动机:
- 整数
- C语言标识符(字母或下划线开头,后接字母、数字或下划线)
- 有限自动机一般可分为两类:确定型有限自动机(DFA)和非确定型有限自动机(NFA)。请你自行了解两者的相关知识,分别简述两者的特点,尝试区分一下你刚刚设计的两个有限自动机分别属于哪一类。依据结果尝试回答一下为什么实际编译器使用DFA而不是NFA
词法分析器的C语言简单实现
了解了正则表达式与有限自动机,我们就可以尝试完成一个简单的词法分析器了。
下面我们尝试用C语言实现一个简单的词法分析器,识别以下Token类型:
- 整数(只考虑非负整数)
- 加减乘除运算符与等号(+、-、*、/、=)
- 左右括号((、))
- 标识符(由字母或下划线开头,后接字母、数字或下划线)
- C语言关键字,当前只考虑
int
// 示例输入
int sum = (a + 10) * b;
// 预期输出
[KEYWORD, "int"]
[ID, "sum"]
[ASSIGN, "="]
[LPAREN, "("]
[ID, "a"]
[PLUS, "+"]
[NUM, 10]
[RPAREN, ")"]
[MUL, "*"]
[ID, "b"]
[SEMI, ";"]// 示例输入
int sum = (a + 10) * b;
// 预期输出
[KEYWORD, "int"]
[ID, "sum"]
[ASSIGN, "="]
[LPAREN, "("]
[ID, "a"]
[PLUS, "+"]
[NUM, 10]
[RPAREN, ")"]
[MUL, "*"]
[ID, "b"]
[SEMI, ";"]请你补全下列代码,使之可以实现词法分析功能
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <ctype.h>
// <ctype.h>提供如下函数:
// isdigit(c) -- 判断是否为十进制数字字符
// isalpha(c) -- 判断是否为字母(大写或小写)
// isspace(c) -- 判断是否为空白字符(空格、换行等)
// ...
// 具体详情请自行了解
#define INPUT_MAXSIZE 45
// Token类型定义
typedef enum{
NUM, // 整数
ID, // 标识符
KEYWORD, // 关键字
PLUS, // +
MINUS, // -
MUL, // *
DIV, // /
ASSIGN, // =
LPAREN, // (
RPAREN, // )
SEMI, // ;
EOF_TOKEN, // 结束标记
} TokenType;
// Token结构
typedef struct Token{
TokenType type; // Token类型
char *value; // Token的值(字符串形式)
} Token;
// 全局变量
char* input; //存储输入字符串
int pos; // 存储当前位置
// 初始化词法分析器
void init_lexer(char *input_str){
input = input_str;
pos = 0;
}
// 跳过空白字符
void skipwhitespace(){
// 请补全代码
}
// 读取关键字和标识符
Token read_identifier(){
// 请补全代码
}
// 读取整数(即连续数字)
Token read_number(){
// 请补全代码
}
// 获取Token
Token get_next_token(){
skipwhitespace();
if(input[pos] == '\0'){
Token token;
token.type = EOF_TOKEN;
token.value = NULL;
return token;
}
char c = input[pos];
// 请补全代码
// 如果读取到无法识别的字符,输出错误信息并退出;
// 输出错误信息具体代码如下:
// fprintf(stderr, "Unexpected character: %c\n", c);
// exit(1);
}
// 打印token
void print_token(Token token){
switch (token.type) {
case NUM:
printf("[NUM, %s]\n", token.value);
break;
case ID:
printf("[ID, \"%s\"]\n", token.value);
break;
case PLUS:
printf("[PLUS, \"+\"]\n");
break;
case MINUS:
printf("[MINUS, \"-\"]\n");
break;
case MUL:
printf("[MUL, \"*\"]\n");
break;
case DIV:
printf("[DIV, \"/\"]\n");
break;
case ASSIGN:
printf("[ASSIGN, \"=\"]\n");
break;
case LPAREN:
printf("[LPAREN, \"(\"]\n");
break;
case RPAREN:
printf("[RPAREN, \")\"]\n");
break;
case SEMI:
printf("[SEMI, \";\"]\n");
break;
case EOF_TOKEN:
// 不打印结束标记
break;
}
// 释放动态分配的内存
if (token.value != NULL) {
free(token.value);
}
}
int main(){
char input[INPUT_MAXSIZE];
memset(input, 0, sizeof(input));
printf("请输入要进行词法分析的字符串:\n");
fgets(input, INPUT_MAXSIZE, stdin);
init_lexer(input); // 初始化输入字符串
// 读取并输出字符串中对应的token
Token token;
do{
token = get_next_token();
print_token(token);
} while(token.type != EOF_TOKEN);
return 0;
}#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <ctype.h>
// <ctype.h>提供如下函数:
// isdigit(c) -- 判断是否为十进制数字字符
// isalpha(c) -- 判断是否为字母(大写或小写)
// isspace(c) -- 判断是否为空白字符(空格、换行等)
// ...
// 具体详情请自行了解
#define INPUT_MAXSIZE 45
// Token类型定义
typedef enum{
NUM, // 整数
ID, // 标识符
KEYWORD, // 关键字
PLUS, // +
MINUS, // -
MUL, // *
DIV, // /
ASSIGN, // =
LPAREN, // (
RPAREN, // )
SEMI, // ;
EOF_TOKEN, // 结束标记
} TokenType;
// Token结构
typedef struct Token{
TokenType type; // Token类型
char *value; // Token的值(字符串形式)
} Token;
// 全局变量
char* input; //存储输入字符串
int pos; // 存储当前位置
// 初始化词法分析器
void init_lexer(char *input_str){
input = input_str;
pos = 0;
}
// 跳过空白字符
void skipwhitespace(){
// 请补全代码
}
// 读取关键字和标识符
Token read_identifier(){
// 请补全代码
}
// 读取整数(即连续数字)
Token read_number(){
// 请补全代码
}
// 获取Token
Token get_next_token(){
skipwhitespace();
if(input[pos] == '\0'){
Token token;
token.type = EOF_TOKEN;
token.value = NULL;
return token;
}
char c = input[pos];
// 请补全代码
// 如果读取到无法识别的字符,输出错误信息并退出;
// 输出错误信息具体代码如下:
// fprintf(stderr, "Unexpected character: %c\n", c);
// exit(1);
}
// 打印token
void print_token(Token token){
switch (token.type) {
case NUM:
printf("[NUM, %s]\n", token.value);
break;
case ID:
printf("[ID, \"%s\"]\n", token.value);
break;
case PLUS:
printf("[PLUS, \"+\"]\n");
break;
case MINUS:
printf("[MINUS, \"-\"]\n");
break;
case MUL:
printf("[MUL, \"*\"]\n");
break;
case DIV:
printf("[DIV, \"/\"]\n");
break;
case ASSIGN:
printf("[ASSIGN, \"=\"]\n");
break;
case LPAREN:
printf("[LPAREN, \"(\"]\n");
break;
case RPAREN:
printf("[RPAREN, \")\"]\n");
break;
case SEMI:
printf("[SEMI, \";\"]\n");
break;
case EOF_TOKEN:
// 不打印结束标记
break;
}
// 释放动态分配的内存
if (token.value != NULL) {
free(token.value);
}
}
int main(){
char input[INPUT_MAXSIZE];
memset(input, 0, sizeof(input));
printf("请输入要进行词法分析的字符串:\n");
fgets(input, INPUT_MAXSIZE, stdin);
init_lexer(input); // 初始化输入字符串
// 读取并输出字符串中对应的token
Token token;
do{
token = get_next_token();
print_token(token);
} while(token.type != EOF_TOKEN);
return 0;
}要求与提示:
- 实现skip_whitespace函数:跳过空格、制表符、换行符等空白字符,可以处理输入字符串可能存在的多个连续空格符
- 实现read_identifier函数:读取标识符(字母或下划线开头,后接字母、数字或下划线)和关键字(目前只要求能够识别
int),用一个 Token类型变量存储并返回该变量。 - 实现readnumber函数:读取非负整数(0-9组成的数字序列),用一个Token类型变量存储并返回该变量。
- 完善getnexttoken函数:判断当前待处理部分是否是标识符、关键字或数字:如果不是,进行各种运算符、括号和分号的处理
上传补全的函数以及程序运行截图
本题提交方式
出题人联系方式
你好......再见 QQ:195225527